Archetypes and Terminology
Eric Browne - April 2008
This page tries to clarify some of the concepts that are used formally and informally to describe the relationship between terminology (particularly SNOMED) and the informational structures represented by Archetypes.
- The first part, #Archetype nodes, values and terms addresses the concepts of terminology binding vs. term binding (labelled 'constraint_binding' vs 'term_binding' in ADL).
- The second part, #Archetypes and SNOMED, looks at the 3 primary hierarchies in SNOMED most relevant to observations, namely Observable Entity, Procedure and Clinical Finding.
Archetype nodes, values and terms
Terminology binding
Terminology binding is a concept used widely in e-health. Notwithstanding its use as the special concept of term binding, terminology binding usually refers to the association between a data point (node) of an information or data model and the set of terms that can be used to populate that data point's value. Thus, terminology binding is a constraint imposed through a specification, reflecting some business rule. Such a business rule could be internationally agreed, or could be a much more localised constraint, imposed by a local institution or software vendor. In openEHR Archetypes, terminology binding can be specified using the constraint-binding section, particularly with placeholder constraints as described in section 5.3.9 (p62) of the ADL 1.4 specification.
On the terminology side of the binding, there are several approaches. The SNOMED community started with the idea of producing separately packaged subsets of SNOMED for particular usage contexts. More recent developments support the notion of 'Refsets'. This is based on a mechanism for tagging a set of terms within the SNOMED database as belonging to a predefined constrained use set. Any term can belong to one or more such Refsets. For instance, all drugs approved by the Australian Therapeutic Goods Administration could have their descriptions tagged in SNOMED as belonging to the TGA-approved Refset. This mechanism has the attraction that the entire SNOMED distribution remains intact, unlike subsets which are released as separate entities. Both of the above two approaches, which support terminology binding by extension, could readily lead to an unmanageable proliferation of subsets or Refsets.
A more flexible and manageable arrangement is terminology binding by intension (sic). Here, the set of permissible values for a data point is expressed by a query or formula. Intensional data binding is the default for most datatypes. When one wishes to specify a date range, for instance, one does not normally enunciate all of the individual dates within the lower and upper bounds.
Query-based terminology binding is usually performed for a specific datapoint in an Archetype. Subsets and Refsets are usually produced for a domain or realm of use and so may span their terminology binding use across a set of datapoints across several or many archetypes.
Another issue with terminology binding is that of the binding time. Should the constraint be imposed in the Archetype at design time, or in some composition template, such as a hospital discharge summary template. Should such a decision be on an Archetype by Archetype basis, or even a datapoint by datapoint basis. For intensional binding, the actual result set returned from the query can occur late (at runtime) in the execution of the application using the Archetype, meaning that the application can have access to the most up to date terms. The mechanism for terminology binding also introduces additional temporal effects, since most implementations would use indirect binding, i.e. via a reference to a term set, subset, Refset, query, etc. whose resolution is unlikely to occur at the time of the design of the Archetype.
Another complexity which overlays terminology binding, is the effect of changes to the terminology over time, and how different versions of SNOMED can be managed, especially given the potential temporal binding issues mentioned above.
Thilo Schuler: Value sets (fixed or dynamic) may be a useful name for terminology bindings.
[A worked example|Terminology and value sets] of binding SNOMED subset to an archetype and a template is now available.
Term binding
Term binding is an ADL construct used to associate a language-independent string-label (e.g. at0005) with a specific term from a specific terminology. This allows for the name of a data point or Archetype node (as distinct from the corresponding value) to be identified as being the same as a specific term in a terminology. This, in turn, has the potential attraction of allowing language translations through the terminology, where they have not been done explicitly in the Archetype.
But since it is unlikely in the near future that any one terminology, including SNOMED, will be sufficiently comprehensive, widely accessible, and of sufficient quality to allow term bindings for all data points, there seems little reason to impose this extra overhead during Archetype development. One potential benefit is the association between the name of a given data point (term binding) and the set of permissible values for that same point (terminology binding). Where SNOMED has been chosen as the preferred terminology, such an association may help the terminology binding specification process.
Thilo Schuler: Semantic tagging may be a useful name for 'term binding'.
Archetypes and SNOMED
Observations using SNOMED
Most clinical observations have two parts - the name of the thing being observed, and the value or result of the observation. What is being observed is (almost?) always descriptive - the height of a person, the mass concentration of HbA1c in the blood, the level of pain experienced, etc. Thus, these names are candidates for being held in a terminology. So much so, in fact, that HL7 in it's V3 Reference Information Model, calls the name of what is being observed the Observation.code. Not so, the result of the observation. This can be, and often is quantitative. It can be a date or a ratio or one of a host of other datatypes. It can be a compound data structure. Again, in the HL7 V3 Observation class, the result of the observation is Observation.value and has a datatype of ANY. The reason for mentioning HL7 here is that some of the HL7 approach to data representation and messaging has influenced the development of SNOMED. Of particular note is that HL7 has one data structure for recording observations - the Observation class with its code and value just described. The assumption is that data already exists in systems and for clinical communication to another system, each observation needs to be placed into an Observation object and these Observations can be bundled up into a message. There is no notion of predefining different observation structures for different clinical concepts à la Archetypes. Thus, users of HL7 need considerable guidance in how to use SNOMED concepts in HL7
Observation objects (populating the Observation.code, Observation.value and other context-related codes), lest every implementation adopts a different approach, subverting interoperability.
And so to SNOMED. In the following discussion, generic concepts are in lowercase (e.g. procedure), whereas SNOMED names use initial capitals (e.g. Procedure).
Observable Entity
This branch of the SNOMED hierarchy describes mental, physical, behavioural or other characteristics of a person or group that have been, or should or could be observed or measured by a person(s) or machine. Terms from this branch are the ideal candidates to populate HL7's Observation.code, and the ideal candidates for term bindings (see above) in Archetypes for naming Archetype nodes in OBSERVATION or EVALUATION archetypes, if such term bindings are deemed of value. SNOMED's Observable Entity terms inconsistently may contain the word "measure" or "level".
Examples from SNOMED Observable Entity hierarchy:
- Gender
- Height of tumour at cut edge, after sectioning.
- Body height measure
Procedure
This branch of SNOMED describes various healthcare acts undertaken to obtain information about the state of a patient or some aspect of a patient's condition, or to change some aspect of a patient's health. That is, the Procedure hierarchy covers both diagnostic and therapeutic procedures. There is implicitly at least one Procedure for every Observable Entity. However, in practice, there is often not a one to one correspondence. This is partly due to the history of SNOMED development, partly due to the legitimate cases where a procedure has no immediate discernable observable entity (e.g. MRI or CT scan), and partly due to the legitimate cases where several different procedures exist to measure or determine the same observable entity. Given the incompleteness of various parts of the SNOMED hierarchies, it is often tempting when specifying terminology bindings, or even just constructing term sets or Refsets, for potential use as values of observations, to use a Procedure as a proxy for an Observable Entity. This is made even more tempting when the term in the Procedure hierarchy appears to be an Observable Entity, as in "Haemoglobin A1c level", which is a synonym for the same Procedure "Haemoglobin A1c measurement". This should be avoided since it will likely break decision support implementations that depend on and expect to traverse the Observable Entity hierarchy. SNOMED Procedure terms inconsistently may contain the word "measurement". SNOMED Procedure terms should be considered candidates for INSTRUCTION Archetypes.
Examples from SNOMED Procedure hierarchy:
- Gender determination by chromosome analysis
- Urine albumin measurement
- Albumin measurement, serum
Finding
This branch of SNOMED describes clinical findings that might be the result of an intentional observation, or coincidental finding or may qualify the result of an observation. Leaf terms from the SNOMED Finding hierarchy are unlikely to be candidates for Archetype term bindings but could well be candidates for terminology bindings to values in Observation or Evaluation Archetypes. Thus, an evaluation Archetype may contain a node with a term binding of "Level of neuroticism" from the Observable Entity branch, have its values constrained to the three possible Findings - "Low level of neuroticism", "Moderate Level of neuroticism", "High level of neuroticism".
A complication inherent with the Finding hierarchy is that parents of leaf terms will often bear the same or similar name as the corresponding Observable Entity. Thus the need for the rather long winded, "Level of neuroticism - finding". As with the Procedure hierarchy, there may be a temptation to use terms from the Finding hierarchy as term bindings to node names in OBSERVATION and EVALUATION Archetypes. Again, this should be discouraged to avoid compromising decision support implementations.
Examples from SNOMED Clinical Finding hierarchy:
- Gender unspecified
- Male
- Fear of heights
- Has grown in height
- Serum albumin normal
Summary
The relationship between SNOMED and Archetypes is important in building semantic interoperability in health care. However it is critical that we do not bind terms inappropriately to nodes in archetypes that have unambiguous meanings which are not yet represented in the correct part of the SNOMED hierarchy. This will be tempting in the name of expediency. But to do so will do more harm than good.
Addendum
Sam Heard, July 2008
One issue that we probably should address in this document is that the 'binding' to terminology addressed here (and called semantic tagging) is just that. It is at present a tag of a code from a terminology to aid in determination of the meaning if it is ambiguous. On further reflection in discussions with Eric Browne, I wonder if this relationship should always be "Records" as an archetype is a structure for recording information about things in the world. This archetype records that. This might help us with the ambiguity that arises when trying to semantically tag the blood pressure archetype. I have retrieved the terms that have an IS_A relationship with 'Blood pressure (observable entity)' as one would expect that we could say:
openEHR-EHR-OBSERVATION.blood_pressure.v1 _records_ "Blood pressure (observable entity)", SNOMED-CT, 75367002
In fact this is not so ,as the blood pressure archetype does not record all of the children of blood pressure:
Term |
Recorded using blood pressure archetype |
Note |
|---|---|---|
24 hour blood pressure (observable entity) |
Yes |
The time series will allow this |
Arterial blood pressure (observable entity) |
? |
It is really systemic arterial, local should use intravascular pressure |
Arterial pulse pressure (observable entity) |
Yes |
Core data element |
Arterial wedge pressure (observable entity) |
No |
I do not think this is ever used for systemic arterial |
Diastolic blood pressure (observable entity) |
Yes |
Core data element |
Invasive blood pressure (observable entity) |
? |
Is this the site of measurement? Not when someone is invading? |
Lying blood pressure (observable entity) |
Yes |
Position at the time of measurement |
Mean blood pressure (observable entity) |
Yes |
Mean Arterial pressure (per cycle) and average blood pressure over a period of time |
Post-vasodilatation arterial pressure (observable entity) |
Yes |
Need a state model to cover this |
Segmental pressure (blood pressure) (observable entity) |
No |
To measure limb pressure and covered by intravascular pressure |
Sitting blood pressure (observable entity) |
Yes |
Position at the time of measurement |
Standing blood pressure (observable entity) |
Yes |
Position at the time of measurement |
Systemic blood pressure (observable entity) |
Yes |
This is what the archetype measures in the broadest sense |
Systolic blood pressure (observable entity) |
Yes |
Core data element |
Venous pressure (observable entity) |
No |
Covered by intravascular pressure measurement |
Comparison with the mindmap image of the archetype might be helpful:
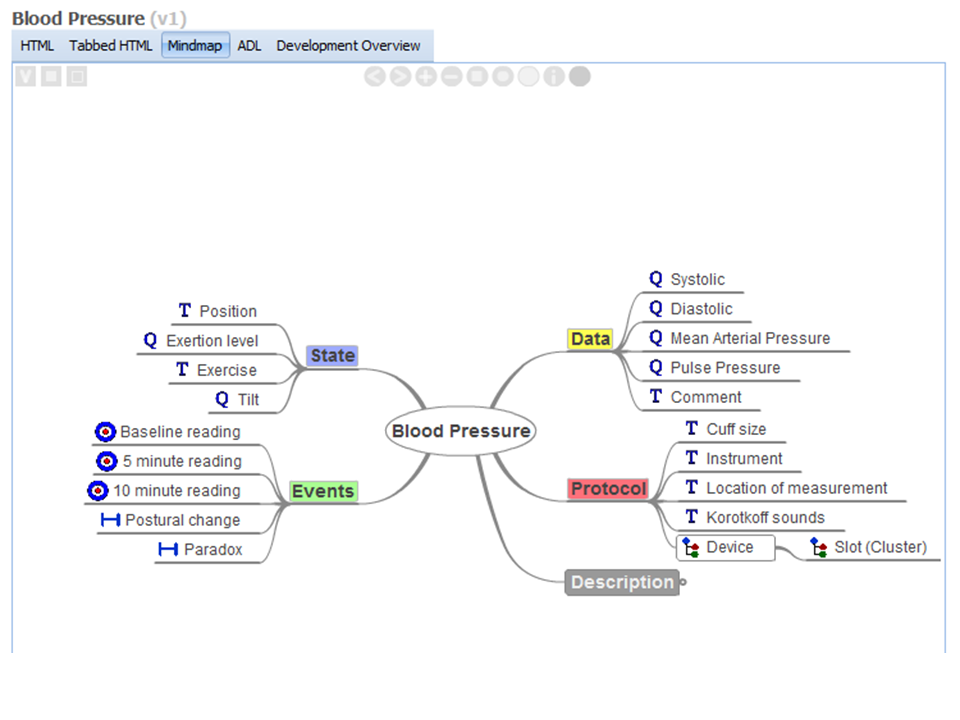
In conclusion, there is much work to be done to maximise the benefit from a close association between the data structures to be shared, the terminology that provides the content for these structures (value sets) and the semantic links with the data points themselves (semantic tagging). Forging a strong working relationship between the IHTSDO and the openEHR Foundation will assist greatly in this process.
References
David Markwell's work for UK NHS CFH program
Use cases for terminology references in archetypes
We should try to collect and discuss use cases for terminology references in archetypes. I divided them into two lists for "terminology binding / value sets" and "term binding / 'semantic' tagging". Please amend the lists and discuss.
Here my definition of terminology binding vs term binding (in par with Eric's above):
Terminology binding - Stating the allowed value for an archetype leaf-node. Can be query based (dynamic, in ADL via constraint-binding) or predefined concept sets (static, in ADL via term-binding)
Term binding - 'Semantic' tagging of intra- and leaf-archetype-nodes with single terminology concepts (in ADL always via term-binding)
Terminology binding / value sets
- Definition of value sets (for value containing archetype leaf-nodes)
- [Thilo] IMO there is no question that SNOMED concepts (or concepts from other terminologies) are important to define value sets. This can be a predefined enumeration (static) or more preferably a query-based statement (dynamic). The advantage of a dynamic statement is that it adapts as the terminology is further developed. Unfortunately there is no standard way to express such queries yet.
- [Hugh] Ocean has a dynamic terminology query language that has been implemented and proven in its tools. This language has recently been put forward to the IHTSDO as a possible candidate for such a query language or at least as an input to the development of the same.
- [Further comments please]
Term binding / 'semantic' tagging
- Automatic translation
- [Thilo] I agree with Eric that term binding is (currently!) very questionable for the purpose of automatic translation. But IMO there are other use cases for term binding (see 2. and 3.)
- Export into non-openEHR formats
- [Thilo] An archetype is self contained model and the meaning of its nodes is defined within the context that the archetype provides. I don't think an external multipurpose terminology can be more accurate. Thus, decision support should be developed based on archetypes and/or templates.
But many non-openEHR formats are less semantically rich e.g. vanilla CDA (i.e. without a constraining template). In order to provide the best possible (most semantically rich) exports into the non-openEHR world the meaning that can be derived from the terminology could be helpful.
- [Thilo] An archetype is self contained model and the meaning of its nodes is defined within the context that the archetype provides. I don't think an external multipurpose terminology can be more accurate. Thus, decision support should be developed based on archetypes and/or templates.
- Terminology-enriched archetype-based decision support
- [Thilo] Although most decision support will be based on the information in the archetype and/or template I think sometimes addional information (e.g. 'calf' is part of 'lower extremity' via ISA relation) can be gained from the terminology.
- Combining archtyped and non-/pre-archetyped data for research
- [Sam, cited from list discussion] A final part of the equation is the area that David Markwell has been working on in the NHS in the UK. He is investigating how to generate computable terminology code phrases from an archetype: that is, how to post-coordinate information captured in an archetype for inferencing in the terminology space. This has benefit in linking with the pre-archetype data and may allow complex research to be undertaken in the future using ontological tools and engines (full source: see mailing list thread).