Ontologies Home
Purpose of this page
The main purpose of this page is start a wider discussion about openEHR and ontology, involving ontology experts. The goal of such a discussion would be to find improvements to openEHR so as to ensure that it really is a model of health information suitable for computerised inferencing and other processing - e.g. decision support, medication interaction analysis and guideline processing. The aim is thus a practical one.
During the history of openEHR its authors learned much about ontology, and made what we believe is a reasonable analysis underlying parts of the openEHR architecture. Now it is time to get people with a lot more experience in this area to have a look at what we have done, and to show us how to improve.
The structure of this page is as follows:
- a bit of background
- success criteria: how will we know if changes we make are good?
- a summary of Biomedical and other ontology efforts that appear to be relevant to openEHR
- a summary of the parts of openEHR that are ontological in nature
- an attempt at synthesis: finding the connections, and particularly, how to make openEHR better.
Background
What are Ontologies and why do we care?
Ontologies are formalised ways of describing aspects of the real world. They are used for two main purposes: a) so that multiple people and computers can agree on the same facts and b) so that computerised inferencing can be performed, usually based on classifying individual facts (patient A has chronically raised blood pressure) in categories (hypertensive person) so as to access facts of the category (increased risk of stroke) relevant to the individual. Many other kinds of reasoning can be done.
There is much work going on in ontologies around the world, including in biomedical ontologies. Most of the work is designed with the following purposes in mind:
- computer-based reasoning on facts e.g. determining from a health record that a patient is at risk of a heart problem, or a candidate for a certain medication;
- aggregation, search and retrieval of data from diverse original source systems, which necessitates rationalisation / mapping of vocabularies used in the original data.
One of the challenges of ontological models is that to work, the data on which inferencing is to be done using the ontology must themselves have a meaning consistent with the ontology. In practical terms this means that the information model(s) of the data must be consistent with or mappable to the ontologies; it also means that the data themselves are likely to be tagged with terms from an ontology. For example, if the data record a 'allergy' for a patient, this must have the same meaning as 'allergy' does in the ontology. However, this is often not the case due to poorly defined terms; 'allergy' might have been used to mean 'an allergic reaction' or 'a diagnosed allergy. Ontologies can help here by allowing the detection of such ambiguities (see http://ontology.buffalo.edu/medo/Cologne.pdf) and by providing well-tested guidelines for how to deal with the corresponding distinctions
Ontologies also exist in software, although most software developers have no idea of this, due to the failure so far of mainstream ICT education to take account of semantics within technical models (i.e. 'class', 'object' or E-R models in the programming sense). Nevertheless, everytime any 'modeller' or programmer creates code, a UML model or an information schema, they are creating some kind of ontology, usually of informational concepts. Software models should be understood as ontologies, because they make commitments to particular notions of the concepts they model - for example kumho solus kr21 , the base data types (Integer, Boolean etc) of programming languages.
A basic categorisation of ontologies used in the ontology world is upper and domain or specific ontologies. An upper ontology is domain-independent, and extremely general; they are applicable over many domains.
If you have never seen an ontology before, you may find John Sowa's top-level categories interesting - this is a well-known example of an upper ontology. Needless to say, this is regarded as by no means the best or most relevant in the biomedical sphere, but it is a useful reference point.
Do Ontologies make sense for Information?
Although at some level all ontologies are 'descriptions of an aspect of reality', for the purposes of this page, we will distinguish between two broad categories of ontology:
- 'ontologies of reality' - ontologies whose subject matter is real things, processes or events, rather than information
- 'ontologies of information' - ontologies whose subject matter is information of any kind - i.e. utterances committed to a medium. Concepts underlying such an ontology are likely to have to do with the process of investigating, recording, reporting or similar ideas.
Obviously 'information' is part of reality, just like everything else, so this distinction needs to be made with care. Nevertheless, we make the distinction because as soon as something is recorded, there is a question of what the recorded form looks like:
- what types of recorded entities are there (e.g. notes, results, diagnoses)
- what is the structure of the recorded information? Clearly quite different recordings could be made of the same event in reality, such as a childbirth
- what are the relationships between items of information? Relationships such as 'see also', 'more detail' and so on make sense here, but not between the entities in reality being reported on.
In openEHR we are interested in ontologies of both kinds. Since the EHR is about recorded information, ontologies of the second kind, of information, are relevant. However, within recorded information of course we expect to find:
- structuring and semantics that are in some way related to the phenomena being reported on. E.g. a record of an abdominal examination is likely to include at least some anatomical terms and characterisations, which should not violate what we know of anatomy, and therefore, should be compatible with ontologies of biomedical reality such as an anatomy ontology.
- references to concepts from ontologies of the first kind, e.g. ICDx or SNOMED terms.
Ontologies of the first kind are therefore just as important. In our opinion, it is not yet clear how they inter-relate....
Some History
At the moment we are not trying to provide a comprehensive summary of the work done in the area of health information ontologies, but it is worth mentioning some of the work of ontological significance that has occurred over the years:
- Theoretical approaches
o 1968: Weed's POMR defined a problem/SOAP model of clinical information #Weed1968
o 1978: Elstein described a hypothetico-deductive model of clinical reasoning (mainly diagnosis) #Elstein1978
o 1992: Rector, Nowlan and Kay described an approach in which EHR information included (paraphrasing) 'what can be said, thought and done for the patient' #Rector1991
o 1994: GEHR (Good European Health Record) an EU-funded project that developed requirements for an EHR and an information model #Ingram1995
o 2003: Tange et al proposed a synthesis of the POMR, Elstein and 'conversation for action;' theory #Tange2003 - Practical approaches:
o 1998- : the Danish G-EPJ ('EPJ' = 'EHR'), which described a cycle very similar to the one used in openEHR #Bruun2005
o 2001-3: the Australian GeHR (Good electronic Health Record) project, an approach that introduced formal 'archetypes' #Beale2000
o 2005- : the Swedish Samba project distinguished 3 kinds of interlinked process: clinical, management and communication #Areblad2005 - Act-based approaches:
o 1992: RICHE consortium devised a method of representing health information in terms of acts carried out in the care delivery process #Riche1992
o 1993- : The HL7v3 RIM (reference information model) is a current approach that attempts to represent health information as acts. #hl7org - Medical terminologies: all medical terminologies with any structure whatever are ontologies of some kind, whether they think they are or not, including:
o MeSH
o ICDx
o Read codes
o SNOMED CT
o LOINC
o and many others
There are also approaches not yet included in engineered systems, but most likely essential for the proper semantics of systems in the future. One such concept is 'referent tracking' which provides a way to ensure that particular events and phenomena observed from the real world are correctly distinguished or known to be the same, regardless of when or how they are recorded. Ceusters2006, Rudnicki2007.
Success Criteria
If we are to take an ontological analysis of openEHR seriously, we need to establish success criteria. These might include:
- defining tests to run on an openEHR repository that would prove correctness or show errors in the underlying ontological approach of the reference model or the archteypes.
- defining design-time tests to be run on archetypes that would show up problems; this might be done using an OWL / protege environment.
Biomedical Ontologies
Relevant biomedical ontology resources to be investigated with respect to the openEHR appears to include the following.
- The NCBO (National Centre for Biomedical Ontology) OCI - the ontology of clinical investigation home page; visual schematic;
- The OBO - Open Biomedical Ontologies home page; the OBO Foundry (where the actual ontologies are); most of these appear to be 'ontologies of reality', although the following ones seem to be about information:
o Ontology for biomedical investigations (OBI)
o Evidence codes - The Basic Formal Ontology (BFO) home page (an ontology of reality), incorporating:
o SNAP, an ontology of substantial entities, tropes (their qualities and functions) and spatial regions
o SPAN, an ontology of process, temporal and spatio-temporal regions
o The paper "Biodynamic Ontology: Applying BFO in the Biomedical Domain" by Grenon, Smith and Goldberg is a good introduction to BFO in the biomedical domain. #Grenon2004
What parts of openEHR have Ontological Relevance?
Within the openEHR environment there are 3 entities that can be considered in an ontological way: the reference model, the archetypes, and terminology (both the internal openEHR vocabularies and well-known external terminologies such as ICDx, ICPC, LOINC and SNOMED CT).
The openEHR Reference Model
The openEHR Reference Model includes an information model which defines many classes. The information model, although relatively basic with respect to some of the ontologies in the biomedical space, nevertheless contains ontological commitments of its own - i.e. formal descriptions of certain real-world concepts relating to recorded health information. The part of the model of most ontological interest is the 'Entry' part, which is formally specified in the openEHR EHR Information Model; it can also be seen online as detailed UML. A summarised UML form of the Entry types in openEHR is illustrated below.
|
There are 5 types of ENTRYs defined: an ADMIN_ENTRY type and 4 sorts of CARE_ENTRY types: OBSERVATION, EVALUATION, INSTRUCTION, and ACTION. The 6th type is called GENERIC_ENTRY, and is designed for mapping into and out of legacy and integration structures such as CEN EN13606, HL7 CDA, message and relational databases. The UML model of this type is here; it is documented in the openEHR Integration IM. All of these types are extremely generic and archetypes are used to define the specific business/domain content models under each of these types - see archetype mindmap for examples. |
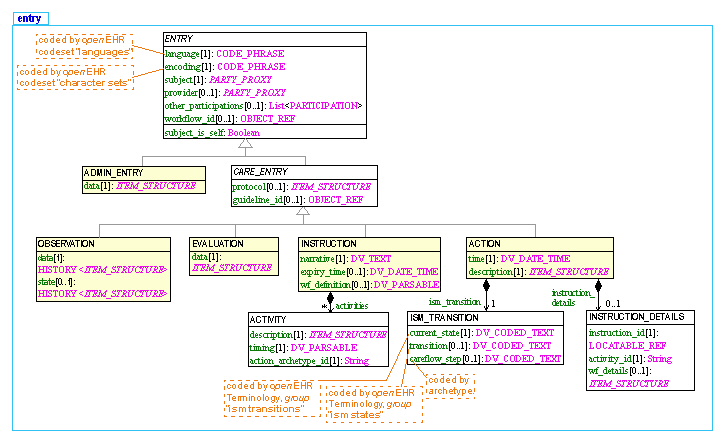
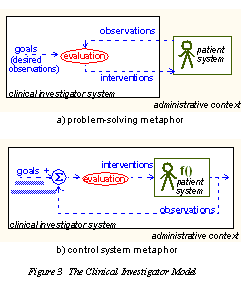
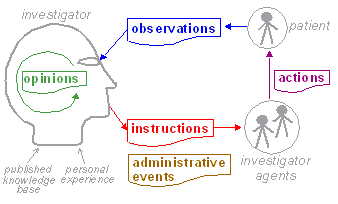
The openEHR Entry model the way it is today has an ontological design which is described in a MedInfo 2007 paper. We can summarise the approach with the following three diagrams. The first is a model of process (shown in two ways); the second shows a cycle of information creation due to the process, and the last shows the information ontology developed in openEHR for recorded clinical information.
|
We model health care delivery as two kinds of process: a clinical process (corresponding to the interaction between a 'clinical investigator system' and a 'patient system') situated within a business process, which is owned by an 'administrative context'. The clinical process constitutes a sub-process of the business process, i.e. it is the main mechanism for the business process to achieve its goal, which is to satisfy a demand for care on the part of the patient. The administrative context corresponds to the health system as a whole, rather than a single enterprise, since from the patient care point of view, the mobilisation of care delivery is carried out by a network of provider organisations. The model can be illustrated in two equivalent ways, as shown in Figure 3. |
|
The terms 'observation', 'evaluation' etc defined above are not themselves the same as information types, since they refer to a variety of phenomena within the process: information from observations, the activity of evaluation, acts of intervention, and goal statements. To be more precise, we are mainly interested in information created by the investigator system, since this notional agent encompasses any person or device who/which performs any healthcare related task, including the patient herself. The investigator system is therefore the creator of all clinical information in the health record, including patient-entered data. A small amount of administrative information may also end up in the EHR, generally created by non-clinical actors in the organisational context.
|
|
The Clinical Investigator Record (CIR) ontology: |
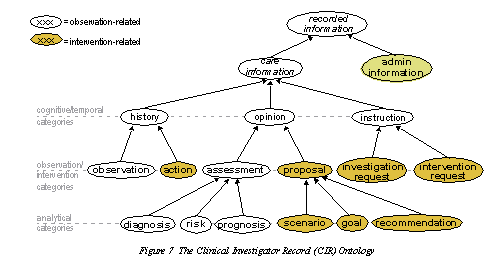
Of the biomedical ontologies mentioned above, the OBI and the OCI appear to be closest in purpose. No proper study of these has yet been made with respect to openEHR. There is also OCRe, which is also broadly under the auspices of the NCBO, and which in the long run may merge with OBI and OCI.
The openEHR Archetypes
In the openEHR approach, most description of the contents of recorded health information is left to archetypes (openEHR FAQ). An archetype can be thought of as a model of some clinical content (e.g. what is recorded in a urinalysis, or an ante-natal visit), expressed in a constraint formalism known as ADL (which has some similarities to OWL). Over 200 archetypes have been defined during NHS projects, Australian GP projects, and openEHR activities (openEHR archetypes page). To go straight to the point, an ontological way of looking at the archetypes that exist is the mindmap view. The structure of each archetype can be viewed by clicking on a node in this view. Another way to view archetypes is with the ADL workbench tool, and with various archetype editors. Example archetypes: Microbial lab observations; Adverse reaction; Examination of named body part.
There are at least two ontological questions with respect to archetypes:
- what should the ontology of archetypes look like (i.e. what should the mindmap look like)?
- what are the correct ontological ways of expressing the structures in an archetype, to ensure correct functioning of the information?
The most important thing we can say with respect to archetypes and ontology is probably this: archetypes are not descriptions of real things like biochemical or anatomical phenomena in the textbook sense (e.g. lik a description of how the heart functions in a physiology book); instead they are recordings of something of interest (observation, evaluation etc) during the clinical process, according to the health professional and following typical clinical approaches. In practical terms then, archetypes are practical in their intent, and only capture what health professionals think they need to record.
Of the work mentioned above, the BFO / SNAP / SPAN ontologies may be a good starting point.
Terminologies and openEHR
Terminologies arranged in hierarchies, such as [SNOMED-CT|http://www.ihtsdo.org/], contain ontological components in that they use relationships between concepts to define other concepts. _to be continued_
The Archetypes and terminologies can be related directly in two ways (described in detail elsewhere):
- A node in an archetype which has a meaning represented in a terminology may be bound to that terminology and the relevant concept; and
- A node in an archetype may constrain the values of a DV_CODED_TEXT to be a specified set of terms from a particular terminology.
In fact, the archetype itself maintains a link to the specified set of terms - the actual set is described within a terminology service and assigned to the link in the archetype.
References
- Rector A L, Nowlan W A, Kay S. Foundations for an Electronic Medical Record. Methods of Information in Medicine, 1991, 30:179-186. citeseer
- Austin JL. How to Do Things With Words. Cambridge (Mass.) 1962 - Paperback: Harvard University Press, 2nd edition, 2005. amazon
- HL7 International. Reference Information Model (RIM). See http://www.hl7.org.
- Weed LL. Medical Records, Medical Education and Patient Care. The Problem Oriented Medical Record as a Basic Tool. Cleveland: Case Western Reserve University press, 1968. google scholar amazon
- Ceusters W, Smith B. Strategies for Referent Tracking in Electronic Health Records. J Biomed Inform. 2006 Jun;39(3):362-78. (ePub 2005 Sep 9, draft, slides presented during the IMIA WG6 workshop Ontology and Biomedical Informatics, Rome, Italy, April 29 - Mai 1, 2005)
- Rudnicki R, Ceusters W, Manzoor S, Smith B. What Particulars are Referred to in EHR Data? A Case Study in Integrating Referent Tracking into an Electronic Health Record Application. In Teich JM, Suermondt J, Hripcsak C. (eds.), American Medical Informatics Association 2007 Annual Symposium Proceedings, Biomedical and Health Informatics: From Foundations to Applications to Policy, Chicago IL, 2007;:630-634. (abstract, draft)
- Elstein AS, Shulman LS, Sprafka SA. Medical problem solving: an analysis of clinical reasoning. Cambridge, MA: Harvard University Press 1978. amazon
- Tange HJ, Dietz JLG, Hasman A, de Vries Robbé PF. A Generic Model of Clinical Practice - A Common View of Individual and Collaborative Care. Methods of Information in Medicine 3/2003. Schattauer GmbH. complete article
- Bruun-Rasmussen M, Bernstein K, Vingtoft S, Nøhr C, Andersen SK. Quality labelling and certification of Electronic Health Record Systems. Studies in Health Technology and Informatics 2005; 116: p47-52. pubmed
- Areblad M, Fogelberg M, Karlsson D, Åhlfeldt H. SAMBA - Structured Architecture for Medical Business Activities. In: Engelbrecht R, et al. (editors) Connecting Medical Informatics and Bio-Informatics. MIE 2005: Proceedings of Medical Informatics Europe; 2005 Aug 28-31; Geneva, Switzerland. p. 1225-30.
- Beale T, Heard S. The GEHR Object Model - Technical Requirements. 2000. complete document.
- RICHE Consortium. RICHE ESPRIT Project. Final Report. Nov 30 1992.
- Ingram D, Lloyd D, Kalra D, Beale T, Heard S, Grubb, P, Dixon R, Camplin D, Ellis J, Maskens A. Deliverable 19,20,24: GEHR Architecture. GEHR Project 30/6/1995. complete document.
- Pierre GRENON, Barry SMITH and Louis GOLDBERG. Biodynamic Ontology: Applying BFO in the Biomedical Domain. From D. M. Pisanelli (ed.), Ontologies in Medicine, Amsterdam: IOS Press, 2004, 20-38. complete article
- Thomas Beale, Sam Heard. An Ontology-based Model of Clinical Information. pp760-764 Proceedings MedInfo 2007, K. Kuhn et al. (Eds), IOS Publishing 2007.