...
- few archetypes use anything but ITEM_TREE because it appears that one 'can never know' if some more detail will be needed later
- TB: but what about things like Apgar, Barthel etc - surely they are linear lists?
- also, it appears that some form of 'table' structure is still needed
- ITEM_TREE, ITEM_LIST etc cannot be nested inside each other arbitrarily.
- the structures complicate the software unnecessarily, without adding much value (this would clearly be true if no/limited use is being made of ITEM_LIST, ITEM_SINGLE) - [question: by "use is being made", do you mean use of the class methods in software or use of the structuring possibilities? The structuring possibilities will remain if a structure_type variable is used.]
- Depending on how you write and divide/distribute software functionality, having ITEM_STRUCTURE subclasses may just complicate class structure and not add any value at all in server/backend/query code and storage. Storing the same structure/presentation info in a structure_type variable will still give GUI code what it needs for validation and presentation but a handful of classes less to implement and maintain e.g. on the server side. Some implementations (or parts of implementations) handle openEHR structures mainly as documents, not objects, thus only stored attributes, not object methods, are used - in those cases the methods of ITEM_STRUCTURE subclasses bring absolutely no value and a structure_type variable would be easier to handle than having to store or infer object type info.
- When learning and presenting openEHR, there will be fewer classes and one level of nesting less to consider, making the design less cluttered.
- "Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away." - Antoine de Saint-Exupery
- archetype paths are made longer and more complex ... MORE INFO REQUIRED - WHAT'S THE PROBLEM?** Paths are used e.g. in AQL queries - shortening or simplification of paths make queries easier to read, write and understand.
- Having fewer nesting levels to traverse in hierarchical database backends (e.g. network-DBs and XML-DBs) or ORM mapping frameworks when fetching data from queries would likely improve performance.
- Shorter paths also means less to parse and translate for the query processing software, but without measuring the impact of this it is not possible to say if it matters very much for performance in practice.
- a clear solution to the pizza problem (multi-value items & UI) is needed
- add a type that is a mixture of CLUSTER and ELEMENT, i.e. has a value and also children, to allow for the fractal nature of data, with a 'summary' value, plus underlying detail
...
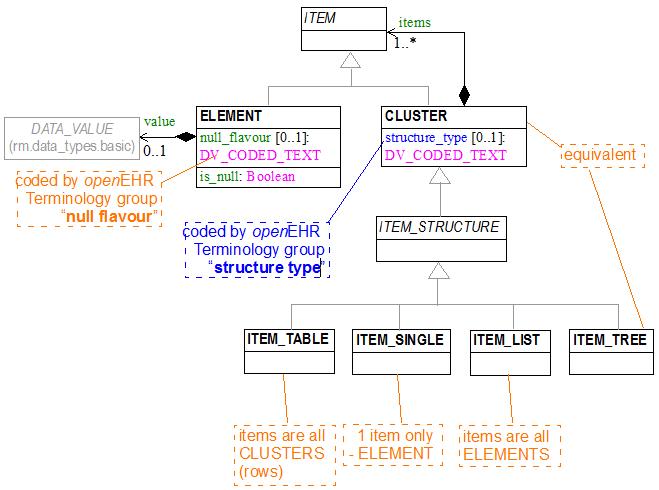
- ITEM_STRUCTURE now inherits from CLUSTER.
- all static declarations in the remainder of the RM for ITEM_STRUCTURE changed to CLUSTER. In theory they should stay ITEM_STRUCTURE, but the problem is that with no static declarations anywhere for CLUSTER or ITEM, CLUSTER archetypes have no place to go, and the CLUSTER type is not detected by my current 'type closure' detecting algorithm. This should probably be changed.
- the types ITEM_TREE, ITEM_SINGLE, ITEM_TABLE, ITEM_LIST could be kept as programming types for manipulating the specific kinds of data structure - they provide a formalisation of the respective constraints on contents (i.e. ITEM_LIST can only contain ELEMENTs, and so on)
- Interior nodes of an ITEM_TREE (aka CLUSTER) can now be other ITEM_STRUCTURE subtypes.
Diagram
Impact Analysis
Component | Impact |
|---|---|
On RM |
|
On existing archetypes |
|
On archetype tooling |
|
On existing RM-1.0.2 based software |
|
On existing RM 1.0.2 data |
|
Discussion
The structure_type attribute of the CLUSTER class is slightly redundant with respect to the ITEM_STRUCTURE descendant types, but makes sense in terms of backward compatibility with existing data. A system that already has ITEM_STRUCTURE + subtypes, + existing instances of those types might be changed to only create CLUSTER-based data in the future, where only the structure_type attribute was used to mark the intended logical structure of a given CLUSTER subtree. Assuming this attribute is used for anything but 'tree', then the result is software that has to implement the same logic as the original ITEM_STRUCTURE descendants, but without having any explicit types to which to attach it.
The second obvious comment one can make on this above model is that ITEM_STRUCTURE is technically redundant (i.e. if building such a model from scratch, it would not be needed). We have left it in here, so that existing static declarations of type ITEM_STRUCTURE in the Release 1.0.2 openEHR RM will remain valid. Getting rid of it would require changing such static references to CLUSTER.
...
Candidate A.1 - Add VALUE_CLUSTER, Remove ITEM_STRUCTURE types
...
In this model, a new class is added that combines CLUSTER and ELEMENT. This reflects the fractal nature of reality. Initially you think you have just an ELEMENT, but later on, people want to start recording more fine detail. In the other direction, information users often want a 'summary' data point for a collection of details. No ITEM_STRUCTURE classes are included at all.
This model is not intended as a 'final solution', just to show what is needed (a CLUSTER-with-value idea), and one way to model it. The technical needs we are trying to meet here are:
...