The problem
There are various long-running problem(s) with archetype node ids in ADL 1.4 and also the current ADL/AOM 1.5 specifications, which are:
- the quirky 4-character top-level codes like at0001, at0003 etc, but lower level codes like at0001.0.1, at0.0.2
- the root node code at0000, which really should be '1' not '0'
- the question of whether all nodes should have codes or not (in openEHR we have not done this; the 13606ers have)
- the lack of separation between node id codes and value codes
- sibling alternative C_OBJECTs under a single-valued C_ATTRIBUTE were not properly distinguished by their paths
In trying to deal with these, I sent an email to some archetype software developers to discuss some more radical ideas, see below, by way of background. I have also been chewing over various posts by Bert Verhees, David Moner, Diego Bosca and others who don't agree with the current rules. After much thought, I decided I don't either.
I have also been thinking on how to make life easier for new implementers of ADL/AOM 1.5 - i.e. people/orgs who never had ADL 1.4 - this includes the Model-Driven Health Tools project led by Dave Carlson and the associated Archetype Modelling Language OMG RfP work led by Robert Lario. My conclusion is that the existing 1.5 drafts have too many annoyances they should not have to deal with.
Lastly, I have had various discussions with Harold Solbrig on how to better represent constraints on terminology elements in archetypes - principally based around using URIs. He has analysed the AOM 1.5 draft in detail, and I think his proposals, in some form will be desirable simplifications.
The main aim here is to create an archetype node-id system that really works for everyone in the same way.
Solution - round 1
The proposal here is to fix the node id system properly. The cost of doing that is to take a new tack on backwards-compatibility of ADL/AOM 1.5 with ADL 1.4:
- make the central ADL/AOM 1.5 specifications as clean as possible - don't worry about syntactical backwards compatibility
- provide a series of updates to ADL 1.4, coming from the 1.5 specs, that are carefully designed to be applied to 1.4 tools, to bring them up to date
- provide rules and tooling to deal with differences between archetype paths, upon which querying is based
- provide a 1.4 => 1.5 upgrade tool to completely convert existing ADL 1.4 archetypes to the new format
Here are the new rules I have implemented:
- renamed the 'ontology' section 'terminology' (an old desire for many!)
- 'id-codes' are now a real thing - i.e. where we had CLUSTER [at0004] we would now have CLUSTER [id4]
- 'at-codes' are used only for value terms, not for identifier 'terms'
- id-codes have their own id_definitions section in the archetype terminology
- id-codes are mandatory on every node in an archetype
- id-codes must have a definition in the terminology.id_definitions section if they are on a C_OBJECT under a container attribute; definitions for other id-codes is optional
- the root id code is now id1, rather than at0000. Specialised archetypes have root ids always of the form id1.1, id1.1.1 etc.
- because of this renumbering, conversion of an ADL 1.4 archetype involves adding 1 to the numbers of all at-codes used as id-codes (but not other at-codes), so actually CLUSTER[at0004] becomes CLUSTER[id5]
- a single id9999 code is used for primitive terminal C_PRIMITIVE_OBJECTs because:
- every node has to have an id
- but terminal primitive constraints don't have the class or node id shown in ADL (since all types are lexically recognised), so no one cares about the id for these nodes
- converting older ADL 1.4 archetypes is a pain if a new id-code has to be created for every terminal node
- it doesn't break the rules - only paths have to be unique, not individual node ids.
- All archetype codes (id, at, ac codes) follow the standard regex (id|at|ac)(0|[1-9][0-9]*)(\.(0|[1-9][0-9]*))*
- Archetype paths only contain id-codes, not at-codes
- unless they happen to have some more complicated predicate e.g. items[id3 and value/defining_code='at12']
- For the moment, only paths have to be unique, not individual node ids.
- right now, there doesn't seem to be any compelling reason to change this.
Example ADL 1.5 archetype here.
Below is the same archetype in the modified ADL workbench.
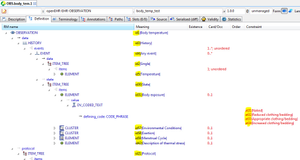 | 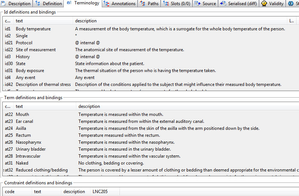 |
|---|
Advantages
These changes should make implementation a lot easier, because now regular rules are used to define all codes at all levels, and also, every node really does have a code now.
One nice advantage of having id-codes and at-codes is that now we can distinguish codes for 'names' from codes for 'values'. We could potentially imagine going even further and arranging the archetype terminology so that at-code value sets are properly grouped.
Possible Problems
One potential problem with the above solution is that since a list of codes will typically be sorted lexically (e.g. in some visual list control), the numeric order is not preserved. I.e. now we get the following in a flat archetype codes list:
id1,
id1.1,
id2,
id22,
id3
It's not yet clear if this matters anywhere.
Solution - round 2
In the next step we would rationalise all coded term constraints to URIs, following recent IHTSDO work, and particularly Harold Solbrig's analysis of both terms-as-URIs and of ADL/AOM 1.5 specifications. This has not yet been implemented, but would have the following effect:
- ac-codes would be converted to at-codes, and the 'constraint_definitions' part of the archetype terminology would disappear
- or possibly, keep the 'ac' code leader, to distinguish, but still merge 'constraint_definitions' into 'term_definitions'
- the CONSTRAINT_REF type would be removed entirely, and its semantics merged into C_TERMINOLOGY_CODE. This will simplify the specification, getting rid of an annoying C_OBJECT subtype, and making terminology constraints more regular.
Conversion of ADL 1.4 archetypes
I have implemented a converter for ADL 1.4 and also existing ADL 1.5 archetypes which does:
- convert the 'ontology' section to be named 'terminology'
- add the new id_definitions section into the archetype terminology
- for all at-codes used as node ids, renumber and reformat them as follows:
- at0000 => id1; at0000.1 => id1.1 and so on
- at000N => idN+1 e.g. at0003 => id4, at0022 => id23
- move all id codes from the term_definitions section to the new id_definitions section
- for all other at-codes, reformat by removing leading zeroes in the top level of the codes
- interior nodes that are missing codes get new id-codes.
- implem guidance: these can be created by injecting a fake code (e.g. id110011 is used in the ADL workbench) early on in parsing (the same code can be used), and then running a post parse processor over the structure, looking for these codes, and converting them to normal id-codes. This is done so that in specialised archetypes, corresponding nodes are found and the id-code replaced with the same code, ensuring that specialised archetypes remain correct.
- leaf C_PRIMITIVE_OBJECT nodes always get the special code id9999.
The above rules can be applied deterministically to convert an ADL 1.4 archetype to a new-style ADL 1.5 archetype, and also (in reverse) to extract a set of ADL 1.4-compatible paths from the new 1.5 archetype.
NOTE: I have build this capability into a new version of the ADL workbench, to avoid others having the write the same converter. For release soon..
Upgrading of existing ADL 1.5 Tools
All current implementations of ADL / AOM 1.5 rules would need to be upgraded if the community decides to go forward with this proposal (or one like it). However, the pain of that should hopefully be offset by the code simplifications that result, and more clarity for future implementers and users of relevant libraries.
Background
The following is an email sent to some archetype software implementers on 9 Dec 2013. The implementation work above is based on a modified version of option A4 below. Not everyone I wrote to agrees with this choice! I didn't like it that much either, but in implementation it turns out to be quite nice.
The following pattern occurs regularly in current archetypes:
ELEMENT[at0021] occurrences matches {0..1} matches {
value matches {
DV_TEXT matches {...}
DV_CODED_TEXT matches {
defining_code matches {...}
}
}
}
It can happen with other alternatives, e.g. DV_QUANTITY, DV_INTERVAL<DV_QUANTITY>; String, DV_DATE and so on. Note that even a single HISTORY object under OBSERVATION.data is potentially an example of this situation.
But in ADL 1.5 it does matter - because paths are how you refer to nodes in a specialisation parent archetype or template. If you want to do an archetype flat-diff, which is needed to process ADL 1.4 archetypes, and also to support ADL 1.5 archetype UI editing, the paths need to be properly unique.
In the current ADL 1.5 draft I have stated the rule to be that at codes would be required in this circumstance, but right now the tools don't implement it. However, I just rebuilt the diffing algorithm properly, and it breaks on the above pattern.
There seem to be a number of alternative strategies from here:
- A1 - force at-codes to be on every object node; consequences:
- => ADL 1.4 archetypes would have to be reprocessed to have at-codes added, as well as definitions for those codes.
- => in the future, all such nodes would need at-codes, which is annoying, because they don't really add meaning
- => even worse, even if there is only a single child of a single-valued attribute (e.g. just the DV_TEXT), it has to have an at-code, because someone can come along later and add a sibling in a revision.
- so now we have to have extra at-codes all over the place, and invent meanings for them
- A2 - force at-codes to be on every object node, but don't require that they are all in the ontology.
- => This solves the path problem, but creates a new problem: you don't know which at-codes are supposed to have meanings (over and above the ones that have to due to containers) - how do you know if your archetype is 'finished'?
- => It might be hard to write a validator to check on definitions of codes if you don't know which codes are intended to have meanings.
- A3 - force at-codes to be on every object node, but maybe do something cunning, like use codes in a different numeric range for codes that don't need meanings.
- not sure if this can be achieved reliably.
- A4 - create a new kind of code to use as node ids in the problem cases, e.g. an 'id' code, i.e. 'archetype id' code, that can be lexically be differentiated from the at-codes.
- => some nodes would now have codes like 'id0003' etc
- => paths would contain a mixture of at- and id-codes
- => it would be clear which codes need meanings in the ontology - just the at-codes.
- => id-codes could be machine-created without reference to the user
- => they could also be safely added to processed ADL 1.4 archetypes
- => this would solve the endless problem about whether C_OBJECT.node_id can be empty or not (now it can't)
- => one possible problem: what if an archetype author decides she wants to define a meaning and term binding for an id-code?
- maybe we make meaning coding optional for id-codes?
- B1 - don't require at-codes, but require some other uniqueness indicator, e.g. am attribute arch_sibling_id like 1, 2, 3 etc.
- => means introducing a new attribute in C_OBJECT that will be populated for any constrainer objects under a single-valued attribute, e.g. for all ELEMENT.value constraints
- => the paths to all object constraints under single-valued objects that don't have an at-code now take the form
- attr_a[atNNNN]/attr_b[new_attr_name='1'], e.g. items[at0005]/value[arch_sibling_id='2']
- note that this you can't just use items[at0005]/value[2], because that just means 'the second' sibling as parsed; if the order is reversed e.g. in a different serialisation or in a specialisation, the same path will refer to a different sibling!
- B2 - don't require at-codes, but detect the situation above when paths are to be generated and create predicates like [rm_type_name='DV_TEXT']
- => the paths to all object constraints under single-valued objects that don't have an at-code now take the form
- attr_a[atNNNN]/attr_b[rm_type_name='RM_TYPE'], e.g. items[at0005]/value[rm_type_name='DV_TYPE']
- this means in a set of paths for an archetype, we have to deal with paths like this, which obviously complicates life
- => nevertheless it does solve the unique identification problem without requiring at-codes