Node+Path Persistence
Overview
Regardless of the particular technology chosen, the persistence design for an openEHR system must take account of the issues raised above: performance and queryability. A general (and quite common) design approach is available, namely the serialisation of subtrees of fine-grained data into "blobs" or strings (e.g. XML or similar). This is most likely to be required to some extent even in an object database, and is almost guaranteed to be needed in object/relational and relational systems. Some powerful variations on the serialisation approach are available with openEHR data than with other varieties, due to the type of paths available.
The following sections describe approaches that are useful with object/relational and relational back-ends.
Basic serialisation
In its simplest form, the serilialisation-into-blobs approach is used to serialise entire top-level information objects into single blobs and store them, a trivial exercise even with a normal relational database - requiring only one column. To provide some query ability, a number of other "indexing" columns are created for attribute values within the blobs which might typically be queried (based on indexes created on the remaining columns). A typical table using this approach might have less than 10 columns and be highly performant. However, there are two drawbacks. One is that the design is not very flexible. If a query needs access to a value not included in one of the special columns, the entire object blob has to be retrieved and deserialised - just to determine if it is in the candidate set for the query. Secondly, adding to or changing which attributes are queryable means changing the table design, and migrating the data.
Nevertheless, this approach has been used in many products quite successfully. It is most suitable when the storage medium is a relational database and the types of queries are mostly known in advance. The following figure illustrates the approach.
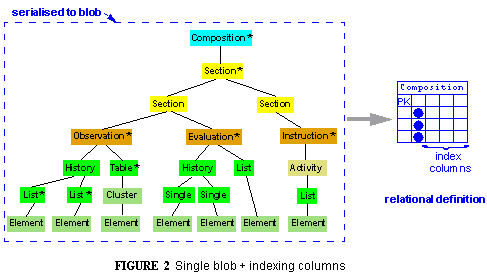
Hybrid Serialisation
A first improvement on the above situation is to serialise some lower-level unit of each data hierarchy. In the openEHR case, an obvious candidate is the Entry level inside Compositions. If Entries are serialised into blobs and stored opaquely, but the containing Sections and Compositions stored transparently (requiring a certain amount of object-relational mapping), then queries that would normally interrogate the transparently stored items will work natively. One very common query in openEHR Compositions is for the event_context data - start and end time of the clinical event, legally responsible clinician, time, location etc - if this is stored transparently, then it will be directly queryable. However data stored below the Entry level (e.g. times in Observations, diagnoses in Evaluations) will be opaque, and still require some kind of special indexing columns.
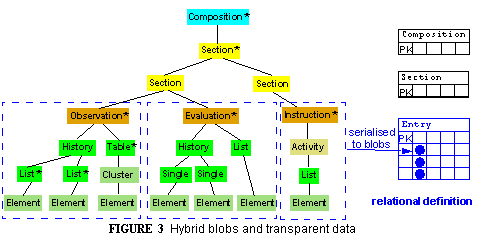
Node+Path approach
The availability of semantic paths in openEHR data provides a generic way of improving the serialised-blob design. In this variant, all data nodes are serialised, and the path of each blob recorded next to it in a two-column table of <node path, serialised node value>, with an index on the path column. The paths need to be unique and sufficient for reconstituting the data on retrieval. The following diagram illustrates the path+node approach.

Fine-grained objects may still be a problem from the performance point of view, in which case the hybrid idea above can be applied in a different way: fine-grained subtrees are serialised to single blobs, with their entire path structure being recorded; higher nodes are serialised singly with single paths being recorded against them. The hybrid path+node approach looks as follows.
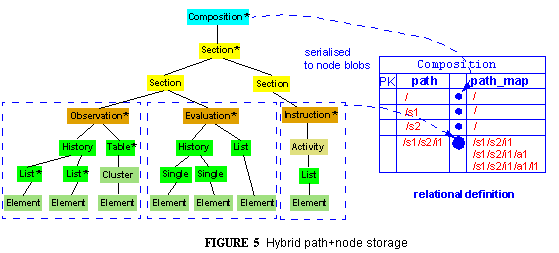
The path+node approach offers two particular advantages:
- the storage model no longer has anything to do with the object model; instead it is simple tabular data that can be stored very efficiently and easily in a relational database
- fine-grained nodes can be queried directly using paths extracted from templates and archetypes.
There are various details to be worked out in implementing this solution, including:
- ensuring uniqueness across all data; remember, archetype-based paths only provide uniqueness on a combination-of-archetypes basis. The full primary key for any given node is the tuple: <Version id, path>, where the Version id includes the GUID of the top-level object, plus which version. This can probably be simplified in an implementation where only the latest version is accessible in the main database view;
- fast parsing / comparison of paths;
- determining the right granularity for grouping in the hybrid variant;
- how to process complex queries, including how to cost sub-parts.
The node+path approach is a refinement of an earlier method described by Beale in 2001, in the original archetypes paper.