Information Model - Terminology Equivalence
Setting the Scene
These pages deal with the key challenge of designing information model ('IM') structures - mostly represented in openEHR as archetypes - and terminology to be semantically equivalent. Why are they not just the same? For many reasons: archetypes are about what information is useful to gather; terminologies (of the ontological kind, like SNOMED CT, and weakly, ICDx, ICPCx) are about what facts are true of certain categories of phenomena of interest in the domain. Thus, an archetype can be designed to represent the common post-partum Apgar data and scores at 1 minute and 5 minutes, whereas an ontology would not necessarily choose either the same data points or time points - neverthless the data points in the archetype should relate to (some) concepts (somewhere) in the terminology, and more importantly, should not violate any underlying ontological rules
[NOTE: in these pages, we have use the SNOMED CT style of notation |text| to mean 'code for "text"', i.e. '|hand, left|' means a code from some terminology for the natural language phrase "left hand" or whicyhever synonym is supported by that terminology, such as "entire left hand". Where codes are included as well, we use 'code|text|', e.g. (in SNOMED CT) '368456002|left hand|'].
Two more examples. Representing the information 'procedure site' in the information model... two choices:
[NOTE: FOR THE MOMENT, THE USUAL '|' character has been changed to '!' because '|' cannot be used in tables, even when quoted in Confluence wiki markup. We hope this is temporary]
The structural way | The terminology way |
|---|---|
parent node
| parent node
|
It is probably obvious to most people why the left side is naive. The problem here is one of ensuring semantic correctness. There will be no problem if only 'left hand' and 'right hand' are used. But what about site = left hand, laterality = right? Or perhaps someone might decide that 'inside' and 'outside' were reasonable as lateralities. Further, not all sites have laterality. And 'left kidney' means a separate organ, whereas 'left lobe of liver' does not. The naive approach leaves it to the information modeller and system to get this right, but in fact the only sure way to do so is with an ontological model of anatomical parts and relationships, which is precisely what a good terminology should be based on. We can also see that the laterality field is unlikely to have any functional use on its own, e.g. as a target of querying (one would never query for all 'left' body sites in an EHR). So it seems pretty clear that the ontological modelling approach is better: it trusts the terminology to know what things have lateralities, and what the possibilities might be, e.g. not only left, right, but upper, lower, superior etc, and also distinguishes properly between the left side of the left eye, and the left side of the right eye, and so on.
So far so good. Now suppose we want to record an evaluation (i.e. essentially a diagnosis) such as 'severe, left upper lobe, pneumococcal pneumonia'. Here are three possible ways to do it.
Purely structural way | Hybrid way | Pure terminological way |
|---|---|---|
parent node
| parent node
| parent node
|
In the pure structural approach, we see the same problem as in the earlier example: laterality is on its own. Similarly, 'severity' is also on its own, when in all likelihood it should be associated with the symptom, since by the same argment as above, only a proper ontology is going to know that 'mild rash' is sensible, but 'mild pregnancy' is not (or even 'mild cardiac arrest', if we want to stick to possible substance reactions).
By contrast, the pure terminological approach uses a syntax (SNOMED CT in this case) to construct a code-phrase representing the codable parts of the information. One obvious problem here is that it is not clear where the non-textual attributes go. Secondly, the use of total post-coordination is likely to make data capture and querying more difficult.
The middle way uses both information model attributes and post-coordination. None of the above is intended to provide answers, merely to explore the questions. Some of the issues we can think of that make it very likely to need to use multiple (rather than one) information attribute are:
- the fact that not all data points are codable, or even textual; and the fact that order is often important - non-text information can easily be mixed in with textual information;
- some data points will be separately queried later on, e.g. 'body_site' is a likely target of a query that may ignore any 'procedure' that might also be recorded. Query performance in production systems with large numbers of EHRs and/or clinical study data will be crucial to the usability of those systems;
- the relationship of clinical models with data capture. Currently, clinical models in the form of templates are often used as a basis of creating data capture screens, display forms, and reports.
On the other hand, it is clear that some post-coordination makes sense, since:
- we need to rely on the underlying ontology (exposed through terminology) to correctly specify things like laterality, possibly severity, and probably some other 'tightly bound' concepts;
- things such as 'laterality' are not useful on their own, as they will never be separately queried for.
The question is: how far do we go in either direction? What is the meeting point?
A potential general answer may be available. Consider the example above: what if the structural example (say the middle one, which might be optimal) and the pure terminology post-coordination could be shown to be equivalent? This would at least mean establishing a congruence between the attribute names used in archetypes and those used in the terminology grammar (i.e. the names in blue). Following that, if particular 'preferred patterns' were defined for structuring various categories of clinical statements, archetypes could be designed so as to be either directly congruent, or to have a clear transformation relationship with terminological equivalents.
This page and its children explore these issues in more detail.
A Comparison of approaches
If terminology were to be relied on to code most/all of any clinical statement (possibly in addition to non-coded attributes, mainly to do with context), some kind of structural discipline is needed. Current thinking in IHTSDO is centred on the idea of 'design patterns', which have been described by Kent Spackman in this slideshow (PDF).
There are three basic categories of information represented in the examples, which are due to the SNOMED modelling approach: structure, values and context.
Here is an example from the slides (slide 59) of the clinical statement 'knee jerk reflex reaction = ++', drawn out as a tree, with relationship terms in blue:
SNOMED expression | openEHR expression |
|---|---|
Situation
| OBSERVATION
|
Comparisons between information model and terminological approach:
Values
Firstly, the question of value representation. Here an ordinal value is used, '++'. There are various problems here:
- in general values like all integers, reals, dates and times and so on cannot realistically be represented in SNOMED
- the ++ value here is a coded term, not a computable value, so we can't do any computing to compare ++ to +++ or + and determine which ones are larger or smaller. With the openEHR DV_ORDINAL data type, both terminological representation and mathematical comparison can be achieved.
- values are often not single, but can have their own structure, e.g. a time series of BP values, with a systolic and diastolic at each 5min time point, or an Apgar score value at 1 minute and 5 minutes. How this would be represented in a pure SNOMED structure is not clear. In the example above, we have shown 2 knee reflex recordings.
- the ordering of values and other attributes can be important, regardless of whether they are coded.
Since values can in general be a mixture of any data types, the overall structure for representing values has to be an information model style structure. It is not clear what the value of trying to put any values inside a SNOMED codephrase would be, given that this won't work in the general case.
Temporal Context
The temporal contexts expressible in SNOMED are classifiers, rather than actual times. The actual time of the observation still has to be represented elsewhere.The possible classifiers appear to include:
- 'current or specified time'
- 'in the past'
- 'all times past'
- presumably some 'future' values as well, to take care of goals, procedures etc.
It is not clear what use a classifier like 'current or specified time' is, since all this is saying is that the observation was true at some time that has to be stated elsewhere anyway. If the value was 'In the past' or 'All times past', this is unlikely to be useful for computing either, e.g. to answer a query to do with last 6 months values for blood sugar or whatever, actual times are needed.
It is not clear how or why these values would be created in software, when explicit time values are going to be created anyway. Who is the reader of these temporal classifications?
Finding Context and Procedure Context
In SNOMED, the finding_context attribute is used to represent the status of a phenomenon, and has the following possible values for observations:
known
known but not recorded
known but not reported
known-present (Asserted) \{known or believed to be present\}
definitely-present 100 synonym: definite
probably-present [50-100) synonym: probable
known-possible (0-100) synonyms: possibly present, possibly absent, uncertain
probably-present [50-100) synonym: probable
probably NOT present = Probably absent (0-50]
known-absent (Negated)
definitely NOT present = Definitely absent 0
probably NOT present = Probably absent (0-50]
unknown
unknown - no attempt to ascertain
unknown - unsuccessful attempt to ascertain
asked but unknown
expectation
likely outcome
prognosis
goal
at-risk
The procedure status is expressed with a value from the following hierarchy:
action status unknown
contraindicated
indicated
not done
did not attend
not indicated
post-starting action status
ended
discontinued
done
attended
performed
stopped before completion
abandoned
suspended
in progress
not to be stopped
started
suspended
to be stopped
pre-starting action status
being organized
accepted
planned
requested
scheduled
approved and scheduled
not to be done
cancelled
not needed
not offered
not wanted
rejected by performer
rejected by recipient
organized
schedule rejected
to be done
under consideration
needed
not wanted yet
not yet offered
offered
wanted
was not started
cancelled
considered and not done
In openEHR, an ontology is the basis for classification of information: openEHR_entry_ontology.png. 'Classification' is achieved by the use of various information model classes, such as Observation, Evaluation, Instruction, Action. However, in openEHR, we don't just classify the information, we use all kinds of other information specific to the kind of classification. For example, 'negation' is usually handled by 'exclusion' or 'differential diagnosis' archetypes.
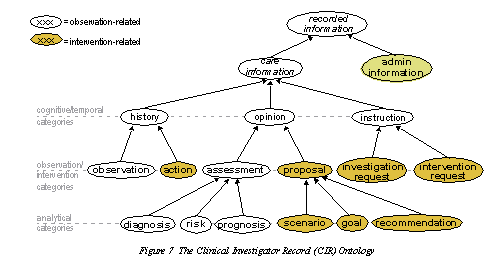{kind=link}
There are philosophical questions here, particularly what the meaning of the subtypes of 'known' within the finding context hierarchy are. SNOMED does not seem to distinguish between opinions, i.e. diagnoses and other kinds of assessments (like prognosis), and observations, and the different kinds of uncertainty associated with both, namely doubt and inaccuracy respectively. ON another dimension, there are phenomenologically different ideas of 'known':
- a clinical assessment was attempted, and the stated finding had a higher of lower level of confidence
- no assessment was / could be attempted.
The kind of 'unknown' that corresponds to the second case is qualitatively different from the notion of 'unknown' due to the first situation, where it is a variety of 'known' with low confidence, or maybe really 'unknown' (i.e. the clinician really didn't know what the symptoms were).
Another concern is that the classifier 'probable' has been mapped to the 50-100% uncertainty band, which is likely to be only some people's idea of the notion of 'probable'.
In a practical information model approach, non-coded attributes are usually used to express particular details of SNOMED's Finding Context value, e.g. % values for differential diagnosis or expectation. In the case of the 2 'unknown' subtypes, these are likely to be expressed using 'flavours of null' in the information model.
The procedure statuses have a large intersection with the openEHR standard state machine model, which is as follows:
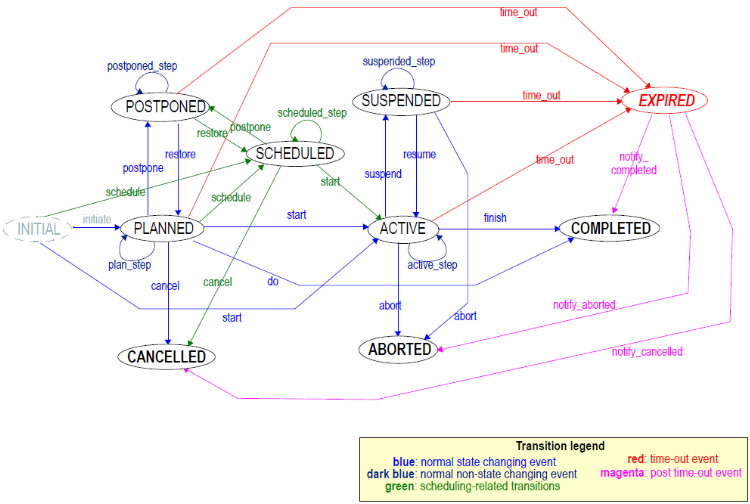
A full analysis of the equivalences is beyond this page here, but we can make some ad hoc observations:
- As a general observation, the SNOMED model doesn't provide any structural model of state, but it implies it linguistically. However, to be usefully computable, some state machine model is needed, otherwise we don't know things like that 'suspended' and 'aborted' imply that the 'active' state was already reached, whereas 'cancelled' implies it was not.
- There is a mixture of states, like 'cancelled' and reasons like 'not needed'; in an information model approach, the latter is not a replacement for the former, it is likely to be additional.
- The value 'done' corresponds to the 'COMPLETED' state. It has two sub-categories, 'attended' and 'performed'. Firstly, it seems unlikely that in all cases that patient attendance means that the intended procedure was done; secondly, if the procedure was in fact done, we can assume that the patient attended (for procedures involving the patient).
Some of the SNOMED terms could be mapped to the codes used to express state names in openEHR, however it is not clear what to do with the others.
Subject relationship context
This context attribute is used in SNOMED to indicate who the statement relates to. It appears to encompass the values:
- 'Subject of record'
- 'Family member'
A comprehensive vocabulary for this purpose in SNOMED appears to be under the 'Person' hierarchy, which subsumes family relationships of all kinds (and also interestingly includes the term 'bum|360852005'). This particular hierarchy looks in need of work to make it safe to use as context.
In openEHR, the equivalent is ENTRY.subject, of type PARTY_PROXY; see here for the latter classes. The types of relationship expressible in openEHR are:
- self, i.e. the subject of the record, via the use of the PARTY_SELF subtype of PARTY_PROXY
- an optionally identified person, via the PARTY_IDENTIFIED subtype of PARTY_PROXY
- an optionally identified person + relationship, via the PARTY_RELATED subtype of PARTY_IDENTIFIED
For the last one of these, the codes come from the openEHR suport vocabulary 'Subject relationship':
- self
- mother
- father
- donor
- unknown
- adopted daughter
- adopted son
- adoptive father
- adoptive mother
- biological father
- biological mother
- brother
- child
- cohabitee
- cousin
- daughter
- guardian
- maternal aunt
- maternal grandfather
- maternal grandmother
- maternal uncle
- neonate
- parent
- partner/spouse
- paternal aunt
- paternal grandfather
- paternal grandmother
- paternal uncle
- sibling
- sister
- son
- step father
- step mother
- step or half brother
- step or half sister
However, in openEHR, there are more details available, as can be seen by the model, including name, identifiers and an external_ref, of type PARTY_REF, which enables a demographic or MPI identifier to be stored.
These different types of relationship necessarily correlate to different types of information being recorded. In openEHR, clinical statements about biological relations may be recorded using the family history archetype, where the information relates to a genetically heritable disease. However, if the information being recorded is something else (e.g. to do with the social relationship of the family member) then some other archetype would be used. In openEHR, the general approach is to use an archetype relevant to the clinical statement being made, allowing for fine-grained details to be recorded. For example, the family history archetype allows the degree and type of genetic relationship to be recorded.
One basic problem with rolling the subject of statement into a post-coordinated SNOMED term is that another solution is required for users of other terminologies, e.g. ICDx or ICPC. Whereas if we adopt an information-model based approach, with the coding of the subject being associated with the model rather than a particular terminology, it will work for any terminology including SNOMED. The key, as with the other context attributes, is to agree on the naming and meaning of these attributes within the information model. This can be done by defining a proper ontology that both information models and terminologies obey.