openEHR EHR Extract
- Thomas Beale
Introduction
A number of EHR Extract models, standards and specifications are available. The main official standard defining this concept, ISO 13606-1, specifies an information model for EHR system Extracts that may contain multiple 'Compositions' for a patient. HL7 CDA defines what could be considered a 'single document extract'. In openEHR an EHR Extract specification has undergone sporadic development. This page presents a significantly updated version, offering greater flexibility than the existing standards, as well as 100% conformance with the rest of the openEHR information models.
The specification is here (PDF ).
Status of this work
[Aug 2010] The work reported on this page was the result of development by Ocean Informatics of the existing openEHR EHR Extract schema, to make it a) more flexible, b) fully archetypable, and c) to improve its ability to accommodate data in 13606 and CDA form. It is not currently a finished proposal. Nevertheless, a fully archetyped and templated model for a discharge summary has been developed using this model.
[May 2011] A full EHR Extract ADL 1.5 template example has been posted at the ADL archetypes Git repo . This model expresses a simple, but realistic discharge summary containing 3 demographic parts and a clinical section. You can use the ADL workbench to configure a profile consisting of the 'Reference' and 'Working' repositories here to see how a realistic EHR Extract would look.
Architectural Overview
The design approach taken is to define a common model of all Extracts, with a plug-in content item specification. Two types of content are currently defined: openEHR EHR content, and 'generic' content, which is designed to accommodate EN13606, HL7 CDA content, and data from proprietary systems.
The key features of the Extract are as follows:
- the entire Extract is archetypable / templatable, including all content;
- demographic content is derived from the openEHR demographic model, which is far more flexible than the 13606 demographic model;
- data from multiple patients can be accommodated in one Extract, e.g. as is typical in communications of pathology results;
- flexible identification for a given 'entity' (i.e. patient or other subject of information), and may include an EHR_id, patient_id, other ids (used for matching), and an indicator of which id is used within the extract for this entity;
- 13606 and CDA like content can be accommodated with a specific content plug-in structure.
The following diagram shows the general structure of a typical Extract, and its relationship to archetype artefacts:
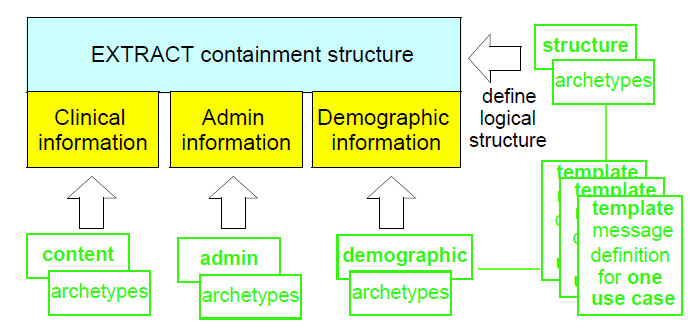
In this structure, an Extract includes clinical content from the source system EHR, optional demographic content, from the source system environment (where this is needed to interpret the clinical information at the receiver end), and administrative information. All of this, and the EXTRACT containment structure, is archetyped and templated. In this approach, one overall template defines one specific Extract type, e.g. 'paediatric discharge summary'. A full example of such archetyping / templating will soon be available on the openEHR test archetype SVN repository .
Element Identification within Extracts
The identification of elements within Extracts is a somewhat tricky topic. One job of the Extract is to transport existing artefact (e.g. document / Composition) identifiers from the source system. However, an Extract needs a way of identifying items within the Extract itself. What this means concretely is that the internal referencing system within the Extract has to work, regardless of how it is implemented in the source system.
The key place references occur within an Extract are from Participation nodes within the main data, to demographic entities, which may or may not be included in the Extract (since they may already be available in a service visible to all Extract-using systems in the overall environment of communication). To achieve this, an Extract specific variant of the openEHR PARTICIPATION class, called EXTRACT_PARTICIPATION is used for participation information built on the fly.
Note: further work is required to identify the possible impact on data in current openEHR systems, and what schema evolution facilities might be required.
Information Model
The information model consists of a number of packages, according to the following:
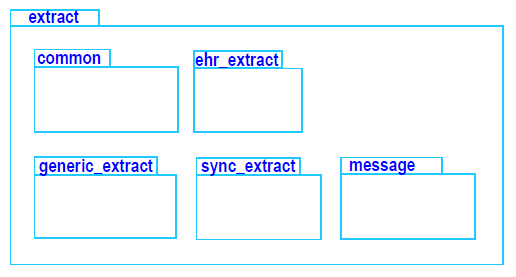
The common package defines features common to all kinds of extracts, and has the following UML model.

The Extract consists of 'chapters', each of which carries either subject-related information (e.g. EHR clinical information) or demographic information. Demographic information is completely optional, and would not be used in environments where a global demographics service or registry is available.
A typical EHR EXTRACT instance according to this model follows the structure shown below:

The blue 'name' fields are generated from archetype and template at-codes, i.e. are completely soft-defined.
EHR Extract variant
An 'EHR' form of the Extract is defined to natively handle data from systems supporting openEHR data export. Its semantics are defined by the combination of the common package and the following EHR package. 
A typical data structure according to this model follows:

Generic / 13606 / CDA equivalent Extract
A second variant is defined to represent data exported in 13606 or CDA format. This model is more permissive and takes account of the version and document semantics of 13606 and CDA. The following model shows the information content for this type of Extract; as for the EHR Extract, this is combined with the common package to define the overall semantics of such extracts. 
A typical instance view is as follows:
