Managed List Model
- Thomas Beale
Overview
This page proposes a solution for representing Managed lists, such as Problem lists, Allergy lists, Medications lists etc. Refer to this Discourse post. The problem and any solution are likely to be strongly related to the Report concept.
NB: although we call these 'lists' in the abstract, they are structurally usually hierarchical heading structures containing content.
Requirements
The distinguishing qualities of such lists:
- are curated, i.e. manually managed (i.e. not query results)
- have content consisting of ‘focal’ and ‘related’ data - ‘focal’ meaning the thematically central data i.e. problems, allergies, medications etc; ‘related’ meaning anything else;
- are not the primary structure in which the thematically focal data (Dxs and the like) are originally recorded
- have their own documentary structure, i.e. something like Section/heading structure
- the focal content is citations of previously recorded diagnoses and/or other ‘problems’
- may have citations of other related previous content, e.g. important observations, past procedures etc
- ?could have have internal de novo content, i.e. not just own Sections, but Entries (probably Evaluations?) created within the List to represent notes? summaries? thoughts about care planning?
- are managed over time by the usual means, with each modification creating a new version.
The above requirements have the following consequences:
- Logical list content, i.e. allergy Dx, other Dx, Medications etc always have their primary representations elsewhere in the EHR; i.e. the cited form in the List is always a reference to something else, regardless of how it is displayed.
- Deleting an allergy from an Allergy list, or a Problem from a problem list doesn't delete the original Allergy or Problem Entry; it deletes the citation from the list. This is very important for the referential integrity of the EHR.
Technical Requirements
The technical requirements are as follows:
- The list should be retrievable as a single entity, i.e. Citation targets should be resolved to their content
- Cited contents should not be counted twice in querying
- A Managed List is a persistent Composition
Design Considerations
To achieve the result that the full List, including all cited contents, is returned through the API on request requires a solution to either persisting or computing the full contents of what the citations point to. The options include (with some obvious dangers listed):
- Persisted Copies: citations are resolved at create time, i.e. they cause copying into the persistent List structure, i.e. the EVALUATION recorded 3 years ago containing my diabetes type 2 Dx is just copied into the Problem List when it is added in the curation process.
- two obvious dangers: copies of Entries are likely to cause duplicates in querying, and worse, if the source content is versioned later (e.g. to correct), the citation will be wrong/out of date; we are breaking the golden rule of IT after all;
- however, making some sort of safe, encapsulated copy is undoubtedly possible, but the versioning problem would also require some special treatment;
- Generated Copies: citation references are resolved at retrieve time on the server when a retrieve request is made such that the full Problem List is instantiated prior to sending through the API
- this requires a model that includes data items that are not persisted, but generated post retrieve - more complicated;
- the query service has to do a different sort of retrieval, so that these duplicate content structures are not created prior to executing the query - again more complexity;
- Generated Serialisations: citation references are resolved at retrieve time, but don’t create structure copies (e.g. a 2nd EVALUATION etc), instead are instantiated in serialised form, e.g. XML or JSON which just need to be rendered to the screen (this kind of approach is documented in the Confluence page on Report representation 1).
- this approach will prevent duplication in querying and any other process that aggregates persisted EHR data;
- but it loses the native openEHR structures that might be useful on the client side.
- Some other (new) native technical representation: some new converted form of the current native structures, e.g. a flattened readonly Entry or similar.
There is also the usual question of whether a Citation refers to the extant (today's) version of the target content, or always the most recent, whatever that may be. Most likely it should refer to the most recent, since if target Entries were reversioned, it was probably for correcting errors.
Archetyping
In this page, the changes needed to the AOM are not included, because they will be more or less the same in call cases - probably a variation on the slot concept.
Solution #1 - LINKs
To implement the above with LINKs, we need to:
- designate some specific values for LINK.type (and maybe LINK.meaning) - see spec here.
- add a new field that contains the resolved value on retrieve;
- possibly some other meta-data fields;
- add something to the AOM to enable link targets to be constrained in a similar way to slot constraints (we need to do this in any case).
The following UML shows a resolved field in a new LINK_2 class, but this could be added to LINK as well.

Features
In the LINK solution, representing a Problem or Allergy list will be a case of attaching LINK objects to SECTIONs.
Advantages
- Probably less implementation work than the View entry approach below;
- The
resolvedfield approach could be used for any kind of LINK, which might be attractive for LINK-following in query processing.
Disadvantages
- The main disadvantage with the LINK solution is that LINKs are attached to other LOCATABLEs, and are not themselves primary content objects (i.e. they are not LOCATABLEs themselves).
- Due to not being LOCATABLE, LINKs do not carry archetype node codes from archetypes, and LINKs acting as Citations cannot be individually identified in the data via archetype codes.
- If we use LINKs to implement Citations, then it is likely that at runtime, a Problem or other list will contain the ‘first class’ Citation LINKs (pointing to the primary data of the list, i.e. problems, Dxs etc from past Compositions) and also other LINKs. If we want to treat Citation LINKs as special, e.g. always ‘follow and resolve’, they will need to be marked as Citations or similar, to distinguish them from other LINKs that are not automatically resolved on retrieved (e.g. some sort of ‘see also xyz’ link, or order tracking Links).
- LINK citations cannot themselves have other LINKs pointing at them (they are not LOCATABLEs);
- if we routinely archetype LINKs within archetypes, it will be harder to distinguish Citations from other LINKs that might be archetyped.
Summary
It might make sense to implement something like the above in LINK anyway, not to solve Citations, but to solve Link-resolution for Links generally.
Solution #2 - Citation Entries - resolved native form
A model based on the addition of new Entry types is shown below. This also includes other kinds of View entry, to show in principle how the solution could be generalised.
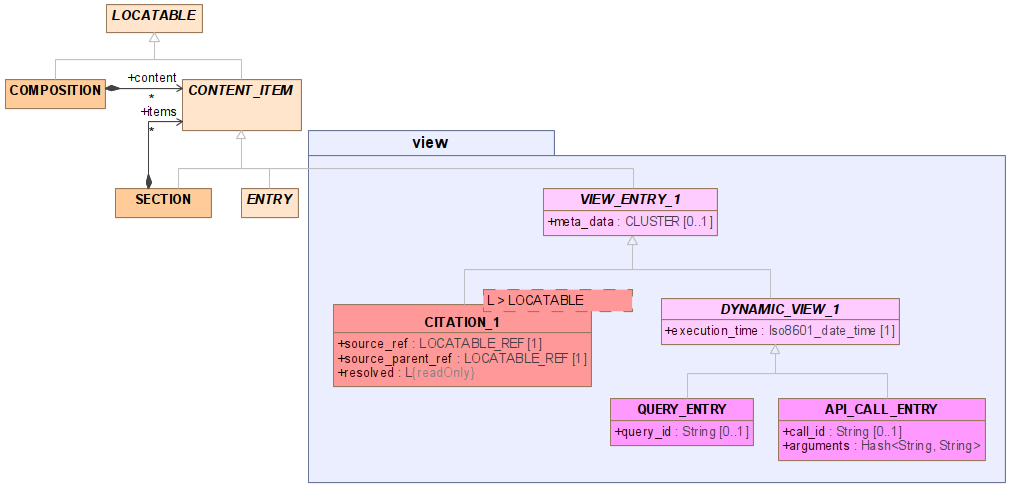
Features
In this form of model, a CITATION is a new kind of ENTRY, which can be included in SECTION structures, and with primary ENTRYs in the usual way. It is generically typed to the reference target, i.e. concrete types are CITATION<OBSERVATION>, CITATION<EVALUATION>, CITATION<COMPOSITION> etc. When a CITATION is persisted, its resolved field is always empty; when retrieved, the resolved field is populated.
It contains a field resolved which is of the native target type, e.g. EVALUATION etc. This might be more useful for immediate computational use on the client side.
The resulting instance structure of say a Problem List in a client is of the form such that CITATION Entries appear under SECTIONs , possibly with other inline Entries containing primary content within the List, and the target of the Citation, i.e. various Evaluations, generally, are one further step from the Citation object.
To define a Problem List as an archetype using this structure would require:
- using
CITATION<EVALUATION>objects whosesource_refis constrained to be a specific archetype, e.g.openEHR-EHR-EVALUATION.problem_diagnosis.v*- this requires a reference form of the slot constraint type to be added to AOM.
Advantages
- A further reason to consider this approach is that these special new ENTRYs can have LINKs attached to or pointing to them, just like any other ENTRY today, but ‘LINK citations’ cannot.
- A CITATION class makes it easier to model and see Citations in an archetype, distinct from other kinds of LINKs that might be modelled as well.
Disadvantages
- The use of the generic type may not be worth the trouble; the
resolvedfield could be typed just toLOCATABLE.
Solution #3 - Citation Entry - resolved serial form
The following model uses a serialised form of the resolved content.
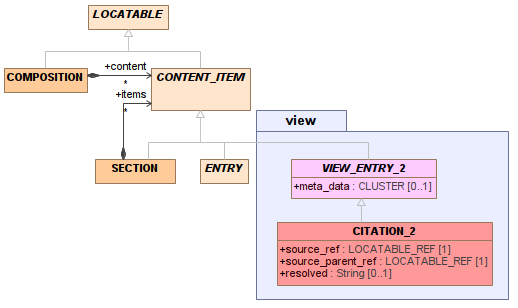
Features
In this version of the model, CITATION is a wrapper for a reference and a serialised resolved form for the source information. This model works mostly in the same way as above, but the serial form representation of the cited content may be easier or safer to use on the client side.
The resolved form could be persisted, rather than computing it every time, since it won't get confused with real entries by the query service.
Advantages
- the serialised approach 'quotes' the target content in a documentary rather than structural form
Disadvantages
- There may be no reliable serial form to choose, since what is convenient is always changing - XML, markdown, various kinds of JSON, etc. On the other hand, which serial form should be used could change over time, based on a call parameter.
Solution #4 - Different Persistence and Retrieval Types
In some sense, the resolved field in all of the above solutions is an anomaly, because it requires different treatment for persistence and retrieval. On committal, it should always be empty; on retrieval, it should be populated - potentially this might be conditional on some request flags. Another approach is to define different types for storage and retrieval, as follows.
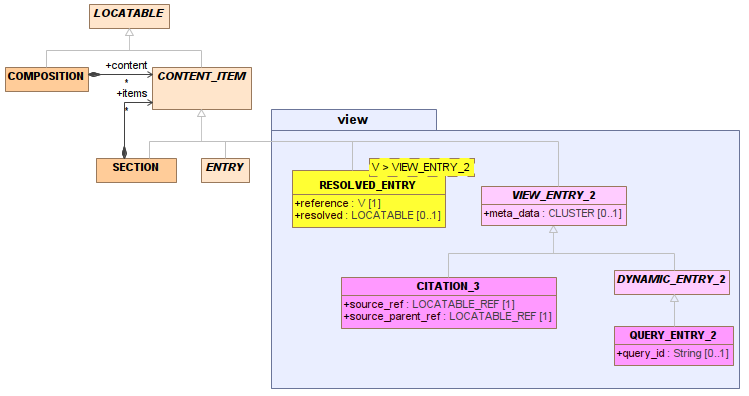
In the above, the persisted form of a Problem List consists of SECTIONs, CITATIONs and possibly other primary ENTRYs, if needed within the list (i.e. orange and violet objects). The retrieved form consists of SECTIONs, RESOLVED_ENTRY<CITATION> etc, each pointing to the original CITATION objects, the resolved target ENTRYs (or other content, e.g. RESULT_SET from a query), and any other primary ENTRYs (i.e. orange and yellow objects, each of which points to a purple object and a copied orange object).
The class RESOLVED_ENTRY doesn't need to be generic as above, this is just one way of doing it to make resolved Entries related to the type of view entry on which they are based.